(500×80px)(450×80px)(460×80px)(470×80px)(2).png)

DeepSeekが最新生成AI「V3.1」発表
混合推論アーキテクチャでエージェント能力を大幅強化

中国のAI(人工知能)開発企業、杭州深度求索人工知能基礎技術研究(DeepSeek、ディープシーク、浙江省杭州市)は21日、最新の大規模言語モデル(LLM)「DeepSeek-V3.1」を発表した。新モデルは混合推論アーキテクチャを採用し、さらにエージェント(Agent)能力を大幅に強化。世界のAI市場での競争を一段と激化させる動きとなっている。
V3.1の最大の特徴は、思考モードと非思考モードを統合的に扱える新しい混合推論アーキテクチャの導入だ。公式発表によると、トレーニング後の最適化により、ツール利用、プログラミング、検索などのAgentタスクで性能が大幅に向上したという。
開発者コミュニティでのテストでは、V3.1はAider多言語プログラミングベンチマークでAnthropicのClaude 4 Opusを上回るスコアを記録。しかもコスト効率も高く、Hugging Face上での注目度が急速に上昇している。
APIも同時に刷新され、コンテキスト長が128Kに拡大されたほか、Anthropic API形式にも対応。さらに9月6日からは新しい価格体系を導入し、夜間割引も廃止する方針を明らかにした。これはサービス拡張後の商業化を加速させる一環とみられる。
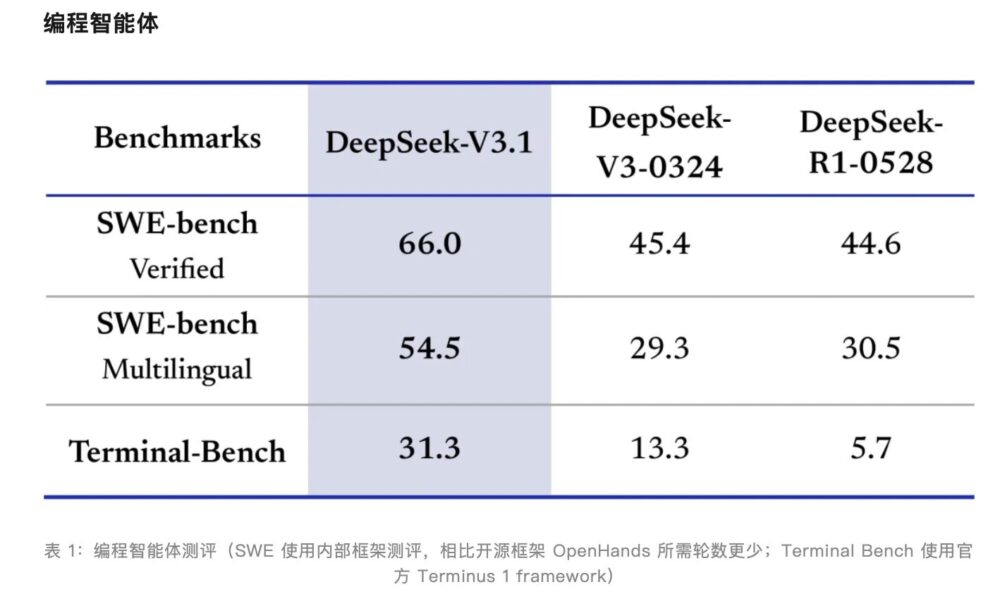
DeepSeekによると、V3.1は「V3.1-Think」モードで思考効率を改善し、従来モデル(R1-0528)に比べてトークン消費を20〜50%削減可能。特にプログラミングや検索領域のAgent能力は顕著に強化され、コード修復やコマンドライン操作、複雑検索において従来モデルを大きく上回った。
さらにオープンソース戦略も継続し、Hugging Faceや魔搭コミュニティでV3.1のBaseモデルと後訓練モデルを公開。パラメータ規模は685Bに達し、追加で8400億トークンの学習を実施した。精度はUE8M0 FP8 Scaleを採用しており、分かち書き器やチャットテンプレートも更新されているため、開発者は最新ドキュメントの参照が必要となる。
今回の発表により、DeepSeekは性能・効率・コストの三拍子を揃えた次世代モデルを提示。自動化プログラミングや情報検索といった実用分野での存在感を一段と高め、商業化への道を加速させている。
次世代国産チップ向けに「UE8M0 FP8」を採用
DeepSeekは公式発表の中で、「DeepSeek-V3.1」が「UE8M0 FP8 Scale」のパラメータ精度を採用していることを明らかにした。分かち書き器(トークナイザー)やチャットテンプレートも大幅に刷新され、従来のDeepSeek-V3とは明確な違いがあるという。
さらに「UE8M0 FP8は、まもなく発表される次世代国産チップ向けに設計されたもの」と説明。今後のハードウェア進展に合わせた最適化であり、V3.1の性能向上だけでなく、中国国産AIチップとの親和性を高める戦略的選択とみられている。